系统简介:
大数据中不可避免地存在着重复数据,以互联网新闻网页为例,大约60%的互联网新闻网页都是重复的。所谓重复数据,往往指基本内容一致,但具体字样往往还存在着少许差异的数据。不同的业务所定义的重复标准也不尽相同。
灵玖大数据文本去重解决方案能够识别各种类型的重复数据,有效降低数据冗余。
主要功能:
能够从大数据中快速识别出重复冗余数据;针对不同的业务类型,可以定制不同的重复标准。
应用案例:
灵玖大数据特征提取已经集成在多个公司的业务系统中。
图1为针对同一机构不同简写、别名及笔误造成的重名问题,可以从大数据业务中自动搜索并检测出重复的机构数据,对数据进行清洗并整合。
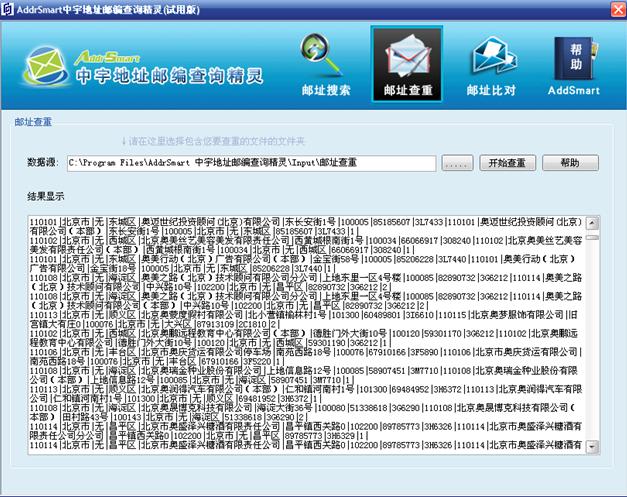
图1:大数据去重应用于中国邮政邮政查重系统
图2为针对新闻转载的问题进行自动识别。
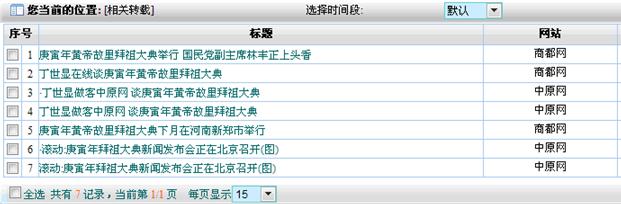
图2:大数据去重应用于新闻转载识别
技术特点:
1. 速度快:内嵌指纹技术和相似性搜索技术,最大限度提升去重效率;
2. 处理精准:不同的去重标准可以定制,更贴切地满足业务需求;
3. 开放式接口:采用灵活的开发接口,可以方便地融入到用户的业务系统中,可以支持各种操作系统。
运行环境:
操作系统:inux2.6及以上;Windows Server
硬件配置:PC即可,内存2G以上